1. Hadoop
하둡(Hadoop)의 HDFS에 대한 기본설명
하둡에서 HDFS에 대해 기본적인 기능을 알아보자. 아래내용은 도서 시작하세요! 하둡프로그래밍(위키북스/정재화지음)에서 HDFS만 발췌/요약정리한 내용이다. 하둡을 처음 공부하는 사람들에게
yookeun.github.io
- 대용량 데이터를 분산 처리할 수 있는 자바 기반의 오픈 소스 프레임워크
- GFS(Google File System)과 MapReduce를 구현한 결과물
- HDFS(Hadoop Distribute File Systme)에 데이터를 저장하고 MapReduce를 이용해 데이터를 처리함
- 여러 대의 서버에 데이터를 저장하고 저장된 각 서버에서 동시에 데이터를 처리하는 방식
- 트랜젝션이나 무결성을 보장해야하는 데이터처리에는 적합하지 않다
- 배치성으로 데이터를 저장하고 처리하는데 적합한 시스템
2. HDFS (Hadoop Distribute File System)
- 대용량(테라, 페타바이트 이상) 파일을 분산된 서버에 저장하고 그 저장된 데이터를 빠르게 처리할 수 있게 하는 파일시스템
- 저사양의 서버를 이용해 스토리지를 구성할 수 있음
- 블록 구조의 파일 시스템 → 파일을 특정 크기의 블록으로 나누어 분산된 서버에 저장
- 블록 크기는 64 MB 또는 128MB 등의 큰 크기로 나누어 저장
- 블록 크기가 128 MB 보다 적은 경우 → 실제 크기만큼 용량을 차지
# 하둡 환경설정 편집경로
cd /usr/local/hadoop/etc/hadoop
# 환경변수를 설정한 상태라면 cd $HADOOP_HOME/etc/hadoop3. Namenode
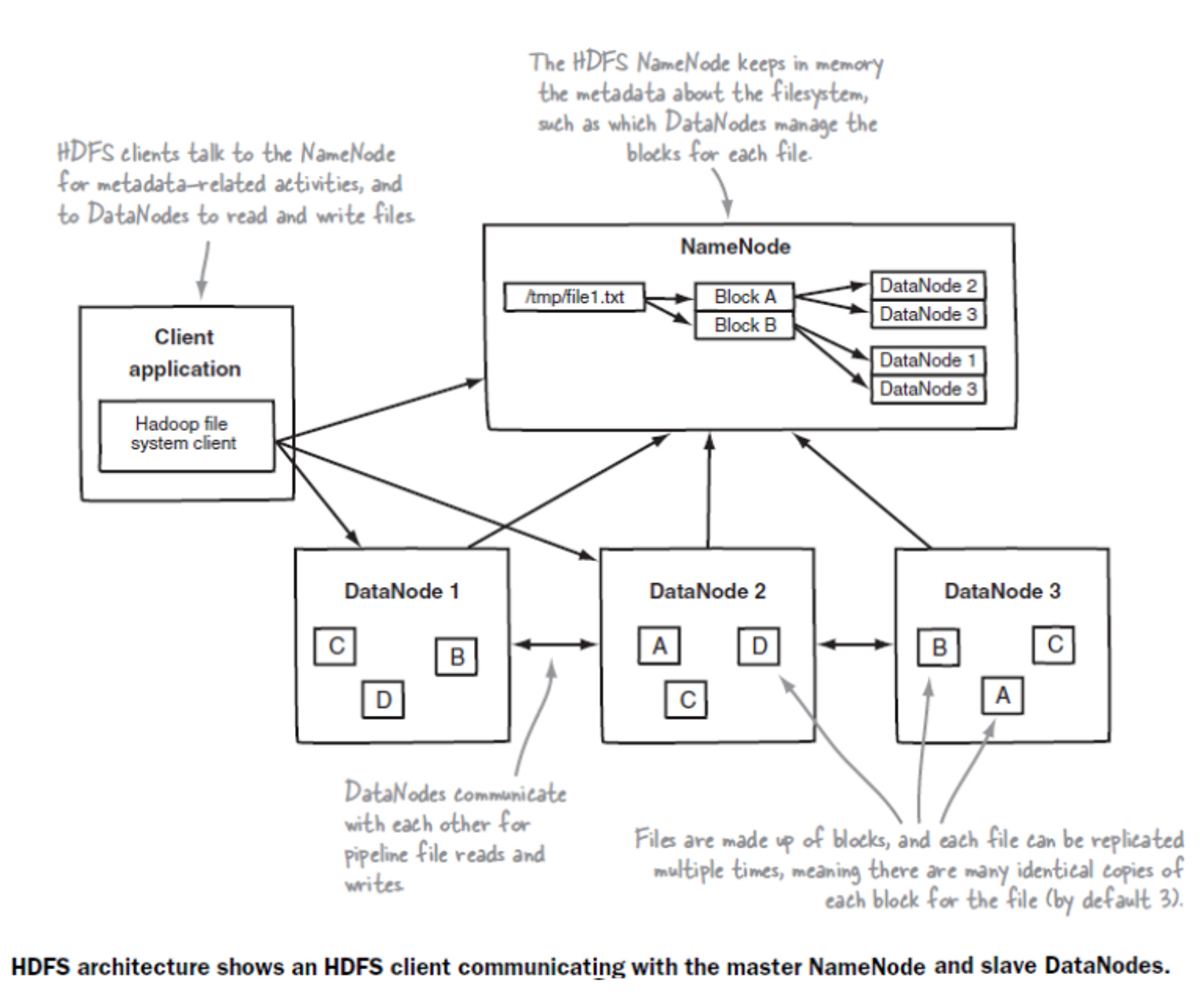
- HDFS은 Namenode(master)와 Datanode(slave)로 구성되어 있음
- Namenode → 파일을 쪼개주는 역할, 쪼개진 파일이 어느 Datanode에 저장되어 있는지 기억(Metadata)
Datanode → 쪼개진 파일을 저장
1. 메타데이터 관리
- 파일시스템을 유지하기위한 메타데이터를 관리
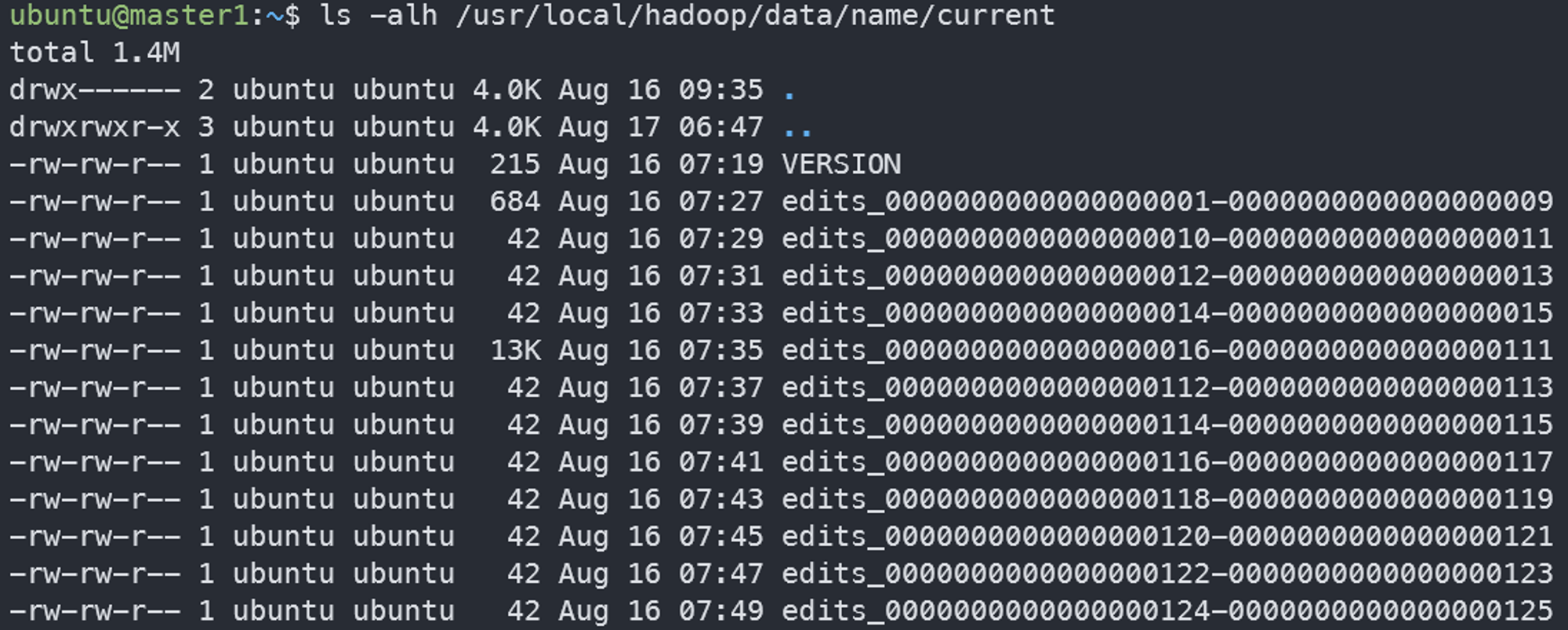

1. 메타데이터 파일종류
- Fsimage 파일 : 네임스페이스와 블록 정보
- Edits 파일 : 파일의 생성, 삭제에 대한 트랙잭션 로그, 메모리에 저장하다가 주기적으로 생성
2. 메타데이터 파일 저장 형태
사용자가 설정한 위치(dfs.name.dir)에 다음과 같은 파일 형태로 저장
ls -alh /usr/local/hadoop/data/name/current
3. 메타데이터
- VERSION : 현재 실행 중인 HDFS의 ID, 타입 등 정보
- edits_0000xxx-0000xxx : 트랜잭션 정보. edits_트랜잭션시작번호-트랜잭션종료번호까지의 정보를 저장
- edits_inprogress_000xx : 최신 트랜잭션 정보. 압축되지 않은 정보
- fsimage_000xxx : 000xxx까지 트랜잭션 정보가 처리된
- fsimage fsimage_000xxx.md5 : fsiamge의 해쉬값
- seen_txid : 현재 트랜잭션 ID
2. 데이터노드 모니터링

- 데이터노드는 네임노드에게 3초마다 hearbeat(3초, dfs.heartbeat.interval)를 전송
- 이를 이용하여 네임노드는 데이터노드의 실행상태와 용량체크
- heartbeat를 전송하지 않는 데이터노드 → 장애서버로 판단
3. 블록관리 (블록리포트)
- HDFS에 저장된 파일에 대한 최신 정보를 유지
- 데이터 노드에 저장된 블록 목록과 각 블록이 로컬 디스크의 어디에 저장되어 있는지에 대한 정보를 지님
- 장애가 발생한 데이터노드의 블록을 새로운 데이터노드에 복제 - 용량이 부족 → 여유 있는 데이터노드에 블록을 옮긺
4. 클라이언트 요청 접수
- 클라이언트가 HDFS에 접근하려면 반드시 네임노드에 먼저 접속해야함
- HDFS에 파일을 저장할 경우 기존 파일의 저장여부와 권한 확인 절차를 거처 저장을 승인
4. Datanode


- 물리적으로 로컬 파일시스템에 HDFS 데이터를 저장
저장할 때 두 가지로 저장 → 로우데이터(실제 저장), 메타데이터(체크섬, 파일생성일자) - 일반적으로 레이드 구성을 하지 않음
- 하트비트 전송
- 블록 리포트
네임노드가 시작될 때 그리고 주기적으로 모든 HDFS 블록을 검사 후 정상적인 블록의 목록을 만들어 네임노드에 전송

블록 파일 저장 상태
- 사용자가 설정한 위치(dfs.data.dir)에 다음과 같은 파일의 형태로 저장
- 블록과 블록의 메타 정보로 저장
cd $HADOOP_HOME/data/data/current/BP-{숫자는 바뀔수 있음}/current/finalized/subdir0/subdir01. blk_12345
- 파일 블록
- 최대 크기가 블록 사이즈(dfs.blocksize) 크기로 생성
- 블록 복제 개수에 따라 동일한 이름의 블록이 여러 개의 노드에 생성 됨
2 . blk_12345_29082353.meta
- 블록의 메타 정보
5. 네임노드 구동 과정
- Fsimage를 읽어 메모리에 적재
- Edits 파일을 읽어와서 변경내역을 반영
- 현재의 메모리 상태를 스냅샷으로 생성하여 Fsimage 파일 생성데이터 노드로부터 블록리포스를 수신하여 매핑 정보 생성서비스 시작
6. 파일 읽기 / 쓰기
- 파일읽기
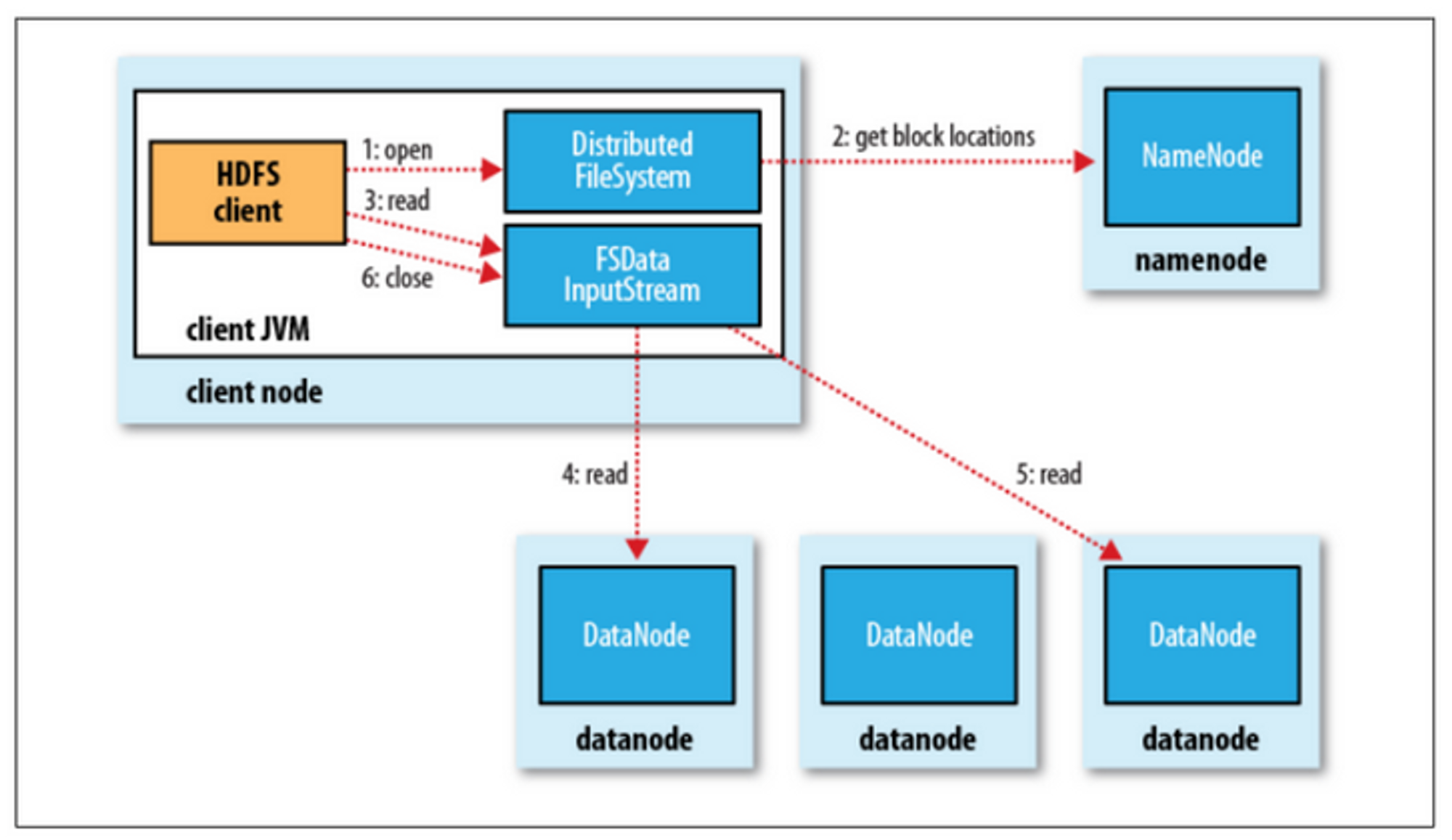
1. 네임노드에 파일이 보관된 블록 위치 요청
2. 네임노드가 블록 위치 반환
3. 각 데이터 노드에 파일 블록을 요청
4. 노드의 블록이 깨져 있으면 네임노드에 이를 통지하고 다른 블록 확인
- 파일 쓰기

1. 네임노드에 파일 정보를 전송하고 파일의 블록을 써야할 노드 목록 요청
2. 네임노드가 파일을 저장할 목록 반환
3. 데이터 노드에 파일 쓰기 요청
4. 데이터 노드간 복제 진행
'DE > Hadoop' 카테고리의 다른 글
| MapReduce (0) | 2023.08.30 |
|---|---|
| Procedure vs Transaction vs Batch (0) | 2023.08.29 |